4. RNA-Seq expression example, components of the airway dataset
4_airway.RmdLet’s look at the airway dataset as an example of a typical small-scale RNA-Seq experiment. In this experiment, four Airway Smooth Muscle (ASM) cell lines are treated with the asthma medication dexamethasone.
The limma voom function will be used to assign precision weights, then the result converted to a weitrix.
library(weitrix)
library(EnsDb.Hsapiens.v86)
library(edgeR)
library(limma)
library(reshape2)
library(tidyverse)
library(airway)
set.seed(1234)data("airway")
airway## class: RangedSummarizedExperiment
## dim: 64102 8
## metadata(1): ''
## assays(1): counts
## rownames(64102): ENSG00000000003 ENSG00000000005 ... LRG_98 LRG_99
## rowData names(0):
## colnames(8): SRR1039508 SRR1039509 ... SRR1039520 SRR1039521
## colData names(9): SampleName cell ... Sample BioSampleInitial processing
Initial steps are the same as for a differential expression analysis.
counts <- assay(airway,"counts")
design <- model.matrix(~ dex + cell, data=colData(airway))
good <- filterByExpr(counts, design=design)
table(good)## good
## FALSE TRUE
## 47242 16860airway_elist <-
DGEList(counts[good,]) %>%
calcNormFactors() %>%
voom(design, plot=TRUE)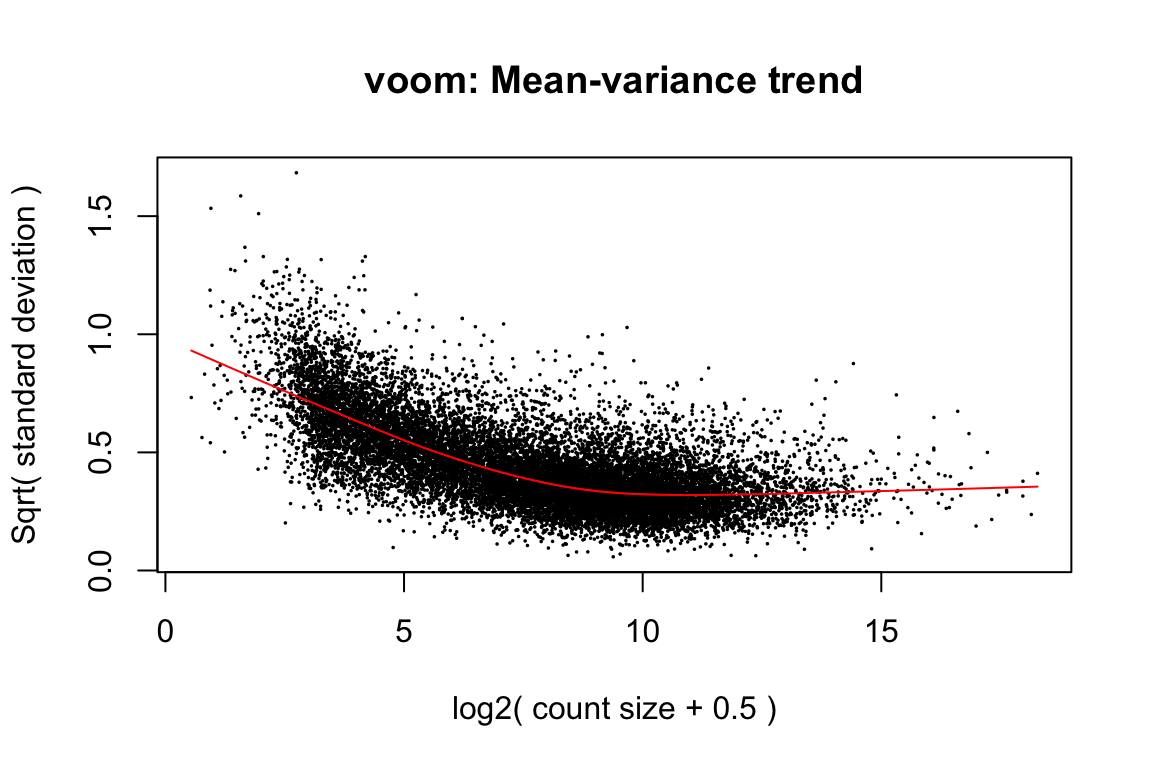
There are many possible variations on this:
voomprovides precision weights. One could instead choose aprior.countforcpmto produce a flat (or at least non-decreasing) mean-variance trend-line.Use
cpmto produce log transformed counts with a small prior count, then useweitrix_calibrate_trendto account for any mean-variance relationship.
Conversion to weitrix
airway_weitrix <- as_weitrix(airway_elist)
# Include row and column information
colData(airway_weitrix) <- colData(airway)
rowData(airway_weitrix) <-
mcols(genes(EnsDb.Hsapiens.v86))[rownames(airway_weitrix),c("gene_name","gene_biotype")]
airway_weitrix## class: SummarizedExperiment
## dim: 16860 8
## metadata(1): weitrix
## assays(2): x weights
## rownames(16860): ENSG00000000003 ENSG00000000419 ... ENSG00000273487
## ENSG00000273488
## rowData names(2): gene_name gene_biotype
## colnames(8): SRR1039508 SRR1039509 ... SRR1039520 SRR1039521
## colData names(9): SampleName cell ... Sample BioSampleExploration
RNA-Seq expression is well trodden ground. The main contribution of the weitrix package here is to aid exploration by discovering components of variation, providing not just column scores but row loadings and respecting precision weights.
Find components of variation
This will find various numbers of components, from 1 to 6. In each case, the components discovered have varimax rotation applied to their gene loadings to aid interpretability. The result is a list of Components objects.
comp_seq <- weitrix_components_seq(airway_weitrix, p=6)
comp_seq## [[1]]
## Components are: (Intercept), C1
## $row : 16860 x 2 matrix
## $col : 8 x 2 matrix
## $R2 : 0.4133809
##
## [[2]]
## Components are: (Intercept), C1, C2
## $row : 16860 x 3 matrix
## $col : 8 x 3 matrix
## $R2 : 0.6561205
##
## [[3]]
## Components are: (Intercept), C1, C2, C3
## $row : 16860 x 4 matrix
## $col : 8 x 4 matrix
## $R2 : 0.8174942
##
## [[4]]
## Components are: (Intercept), C1, C2, C3, C4
## $row : 16860 x 5 matrix
## $col : 8 x 5 matrix
## $R2 : 0.9122109
##
## [[5]]
## Components are: (Intercept), C1, C2, C3, C4, C5
## $row : 16860 x 6 matrix
## $col : 8 x 6 matrix
## $R2 : 0.9542232
##
## [[6]]
## Components are: (Intercept), C1, C2, C3, C4, C5, C6
## $row : 16860 x 7 matrix
## $col : 8 x 7 matrix
## $R2 : 0.9800651We can compare the proportion of variation explained to what would be explained in a completely random weitrix. Random normally distributed values are generated with variances equal to one over the weights.
rand_weitrix <- weitrix_randomize(airway_weitrix)
rand_comp <- weitrix_components(rand_weitrix, p=1)
components_seq_screeplot(comp_seq, rand_comp)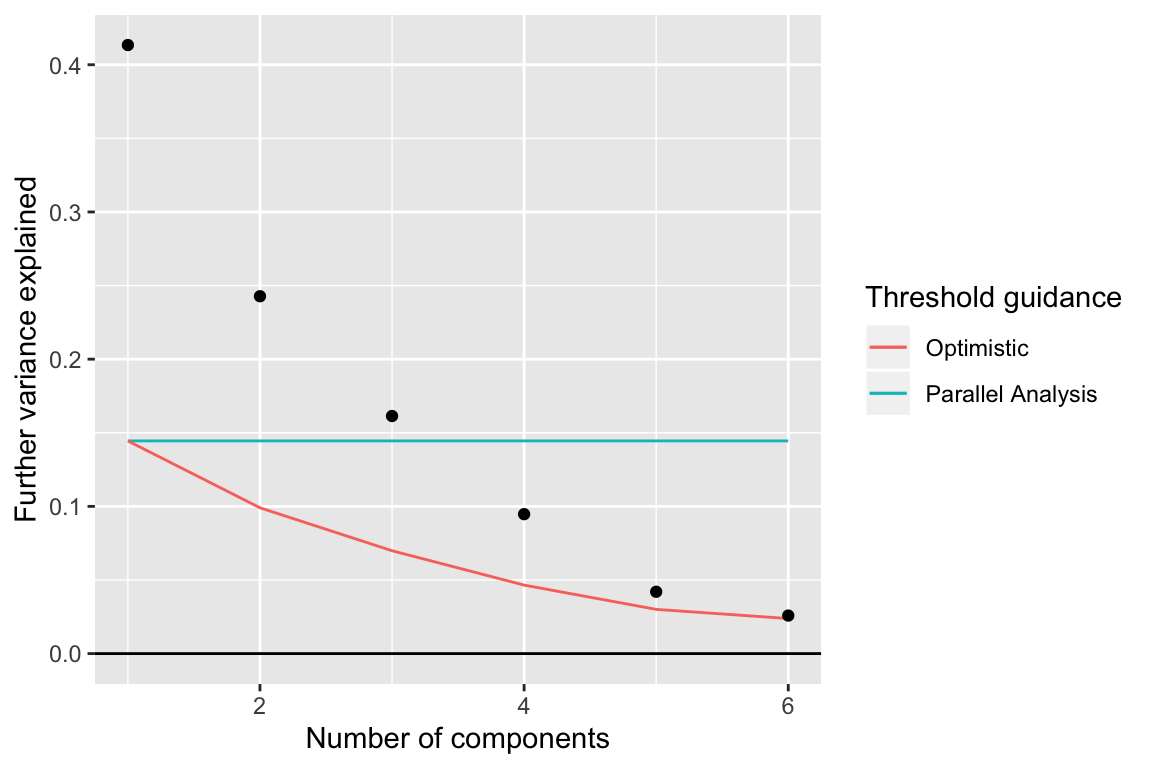
Examining components
Up to 4 components may be justified.
comp <- comp_seq[[4]]
comp$col[,-1] %>% melt(varnames=c("Run","component")) %>%
left_join(as.data.frame(colData(airway)), by="Run") %>%
ggplot(aes(y=cell, x=value, color=dex)) +
geom_vline(xintercept=0) +
geom_point(alpha=0.5, size=3) +
facet_grid(~ component) +
labs(title="Sample scores for each component", x="Sample score", y="Cell line", color="Treatment")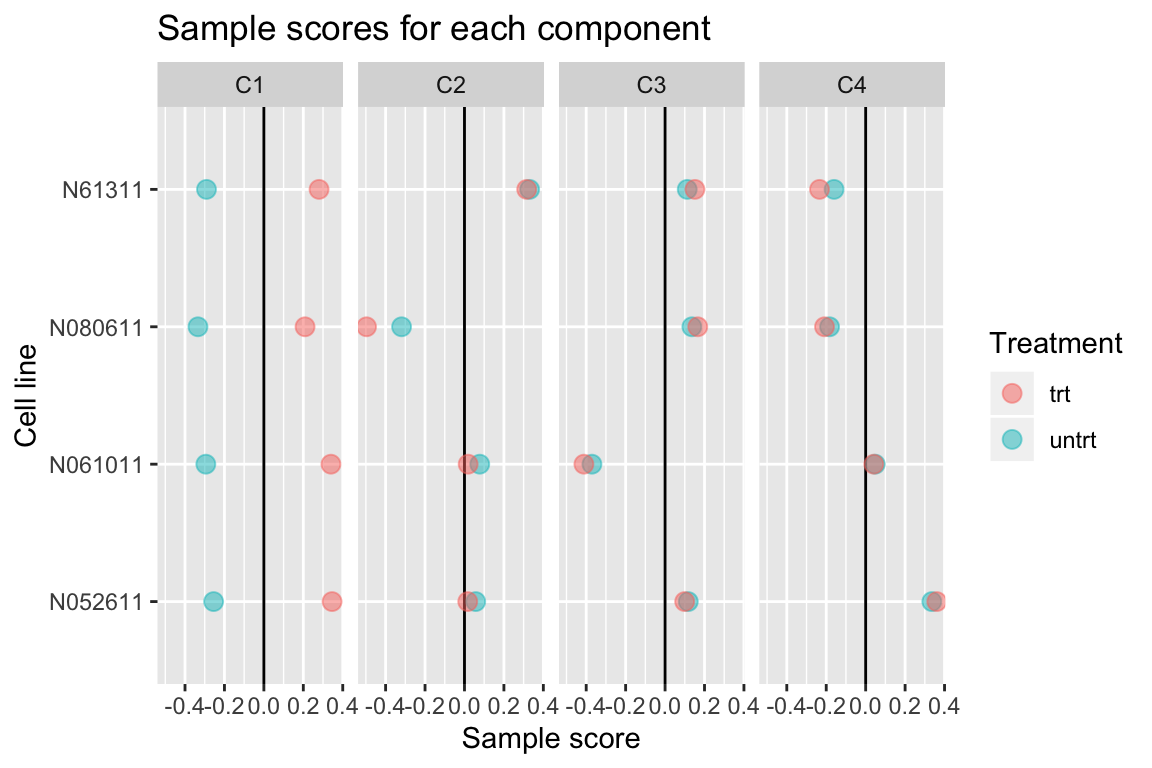
comp$row[,-1] %>% melt(varnames=c("name","component")) %>%
ggplot(aes(x=comp$row[name,"(Intercept)"], y=value)) +
geom_point(cex=0.5, alpha=0.5) +
facet_wrap(~ component) +
labs(title="Gene loadings for each component vs average log2 RPM", x="average log2 RPM", y="gene loading")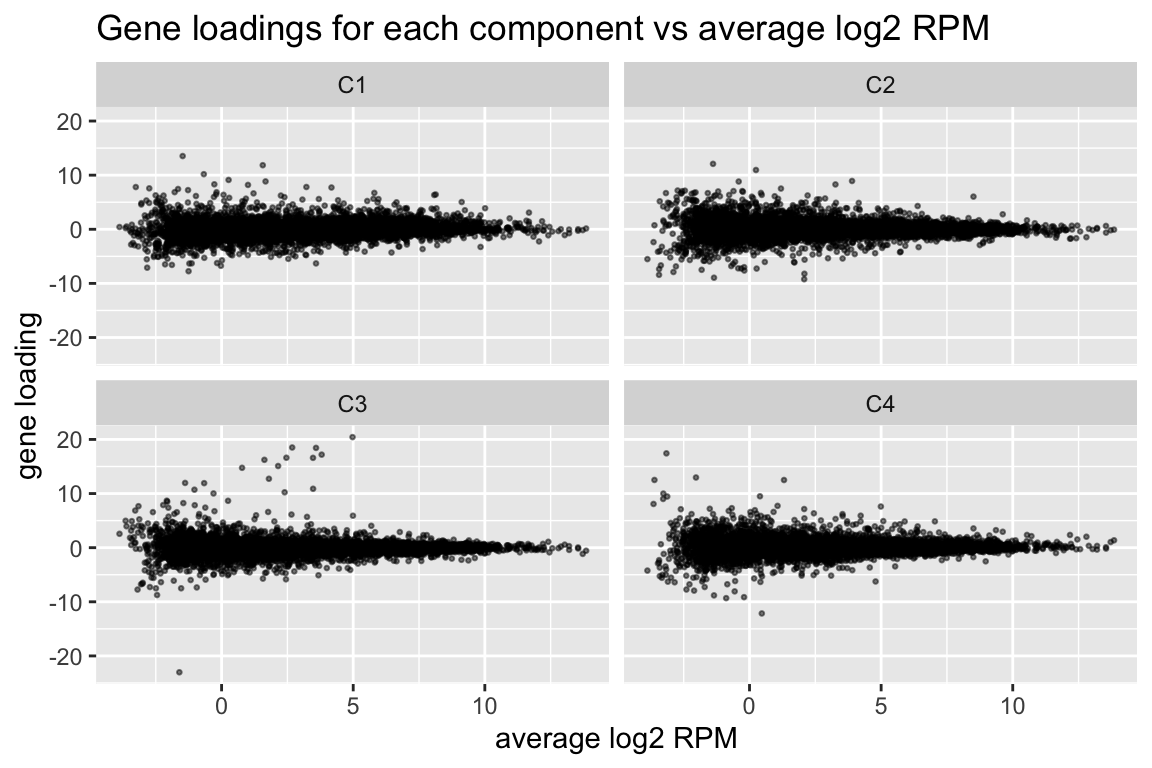
Without varimax rotation, components may be harder to interpret
If varimax rotation isn’t used, weitrix_components and weitrix_components_seq will produce a Principal Components Analysis, with components ordered from most to least variance explained.
Without varimax rotation the treatment effect is still mostly in the first component, but has also leaked a small amount into the other components.
comp_nonvarimax <- weitrix_components(airway_weitrix, p=4, use_varimax=FALSE)
comp_nonvarimax$col[,-1] %>% melt(varnames=c("Run","component")) %>%
left_join(as.data.frame(colData(airway)), by="Run") %>%
ggplot(aes(y=cell, x=value, color=dex)) +
geom_vline(xintercept=0) +
geom_point(alpha=0.5, size=3) +
facet_grid(~ component) +
labs(title="Sample scores for each component, no varimax rotation", x="Sample score", y="Cell line", color="Treatment")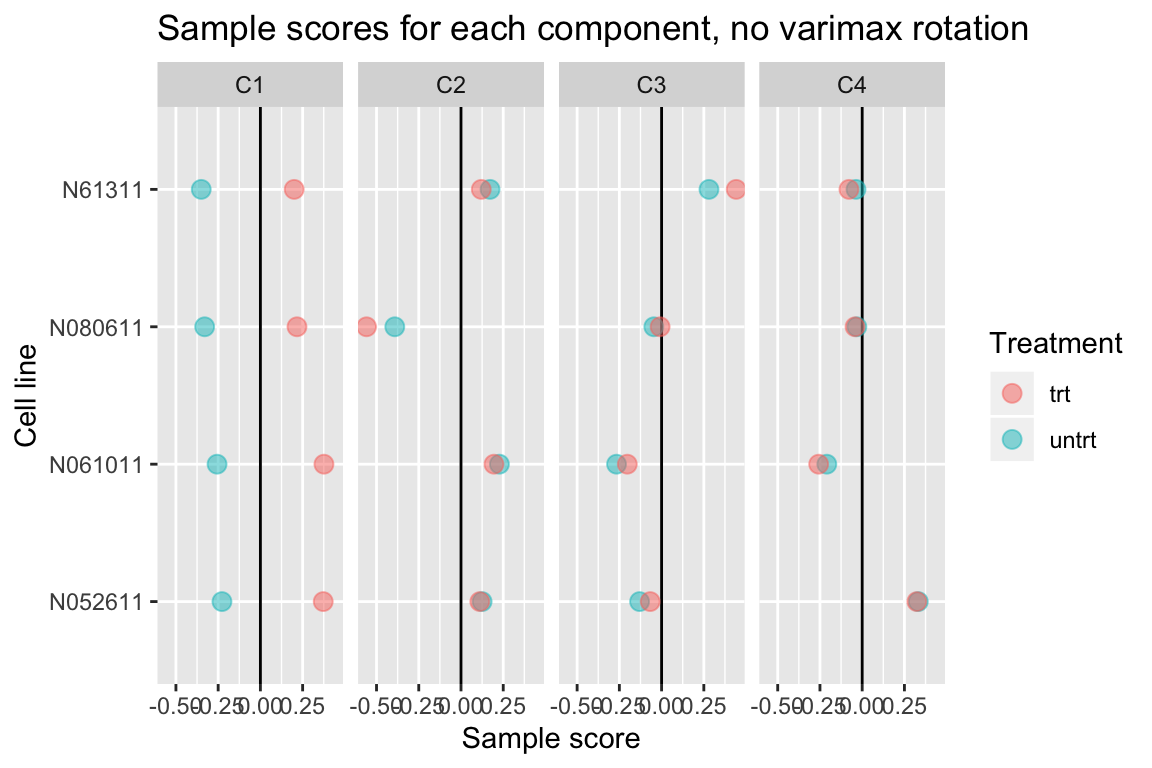
col can potentially be used as a design matrix with limma
If you’re not sure of the experimental design, for example the exact timing of a time series or how evenly a drug treatment was applied, the extracted component might actually be more accurate.
Note that this ignores uncertainty about the col matrix itself.
This may be useful for hypothesis generation – finding some potentially interesting genes, while discounting noisy or lowly expressed genes – but don’t use it as proof of significance.
airway_elist <- weitrix_elist(airway_weitrix)
fit <-
lmFit(airway_elist, comp$col) %>%
eBayes()
fit$df.prior## [1] 6.531096## [1] 1.036364topTable(fit, "C1")## gene_name gene_biotype logFC AveExpr t
## ENSG00000101347 SAMHD1 protein_coding 6.427453 8.135257 46.07562
## ENSG00000189221 MAOA protein_coding 5.584493 5.950559 35.38160
## ENSG00000139132 FGD4 protein_coding 3.721531 5.415341 32.67051
## ENSG00000120129 DUSP1 protein_coding 4.986316 6.644455 31.92671
## ENSG00000178695 KCTD12 protein_coding -4.295197 6.451725 -31.49058
## ENSG00000134243 SORT1 protein_coding 3.567966 7.569410 28.91065
## ENSG00000179094 PER1 protein_coding 5.370151 4.420422 29.44179
## ENSG00000165995 CACNB2 protein_coding 5.590915 3.682244 30.23761
## ENSG00000157214 STEAP2 protein_coding 3.413301 6.790009 27.49205
## ENSG00000122035 RASL11A protein_coding 4.051210 4.886461 27.65426
## P.Value adj.P.Val B
## ENSG00000101347 1.599481e-12 2.696724e-08 18.63745
## ENSG00000189221 1.955539e-11 1.648520e-07 16.61574
## ENSG00000139132 4.157001e-11 1.653757e-07 16.00037
## ENSG00000120129 5.167966e-11 1.653757e-07 15.85715
## ENSG00000178695 5.885257e-11 1.653757e-07 15.72681
## ENSG00000134243 1.318965e-10 2.223775e-07 15.02324
## ENSG00000179094 1.110809e-10 2.080915e-07 14.86859
## ENSG00000165995 8.635872e-11 1.820010e-07 14.75178
## ENSG00000157214 2.119535e-10 2.748874e-07 14.58748
## ENSG00000122035 2.005232e-10 2.748874e-07 14.54112all_top <- topTable(fit, "C1", n=Inf, sort.by="none")
plotMD(fit, "C1", status=all_top$adj.P.Val <= 0.01)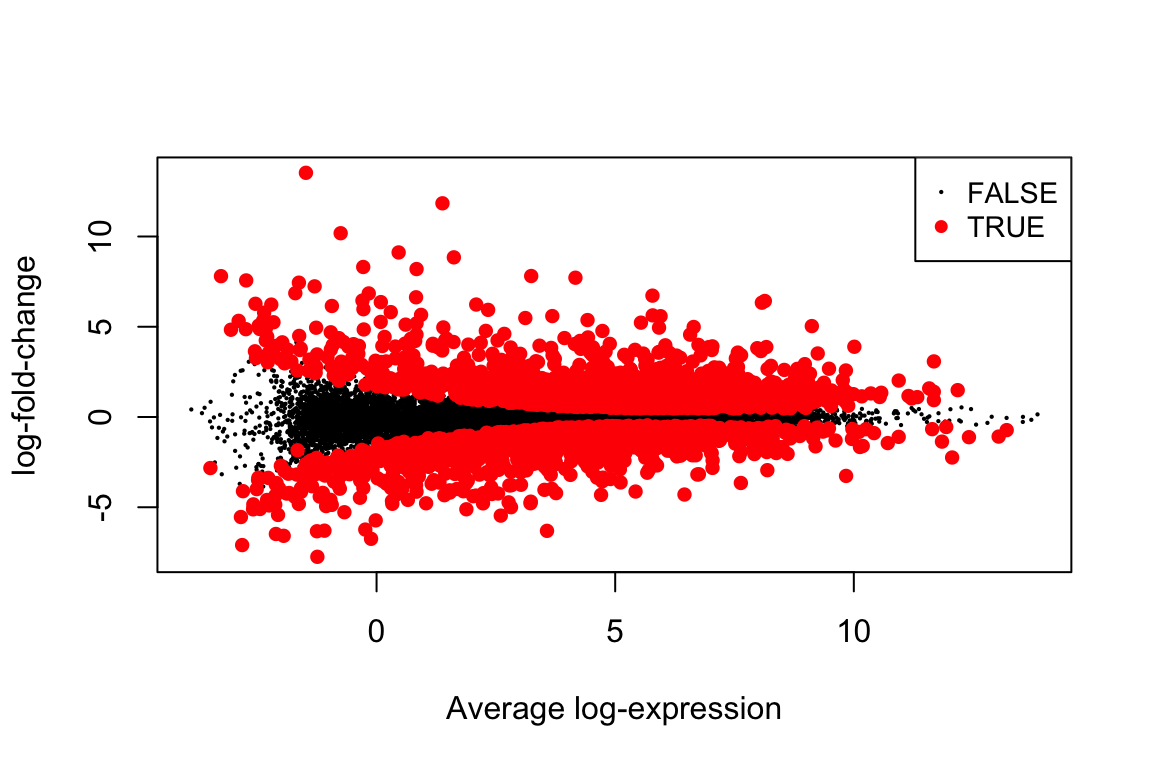
You might also consider using my topconfects package. This will find the largest confident effect sizes, while still correcting for multiple testing.
library(topconfects)
limma_confects(fit, "C1")## $table
## rank index confect effect AveExpr name gene_name
## 1 10918 7.848 13.528918 -1.4798754 ENSG00000179593 ALOX15B
## 2 3029 6.026 11.838735 1.3807218 ENSG00000109906 ZBTB16
## 3 8636 5.927 7.810468 3.2401058 ENSG00000163884 KLF15
## 4 9976 5.927 9.116726 0.4626392 ENSG00000171819 ANGPTL7
## 5 7468 5.698 7.717228 4.1669039 ENSG00000152583 SPARCL1
## 6 2066 5.415 6.427453 8.1352566 ENSG00000101347 SAMHD1
## 7 9458 5.184 8.196551 0.8379382 ENSG00000168309 FAM107A
## 8 4755 5.083 8.844567 1.6193300 ENSG00000127954 STEAP4
## 9 8391 -4.869 -6.306789 3.5709602 ENSG00000162692 VCAM1
## 10 15487 4.556 10.181240 -0.7521822 ENSG00000250978 RP11-357D18.1
## gene_biotype
## protein_coding
## protein_coding
## protein_coding
## protein_coding
## protein_coding
## protein_coding
## protein_coding
## protein_coding
## protein_coding
## processed_transcript
## ...
## 5420 of 16860 non-zero log2 fold change at FDR 0.05
## Prior df 6.5