| Life has a texture to it. Each life has its own unique path, but all are variations on a theme. Happiness and sadness pass in their various forms, following well worn trajectories. And if we document these paths, and if we record each trajectory, others might avoid our mistakes, and repeat our successes. And we might do the same of theirs. |
21/1/2004: Single-person version largely complete, still needs polishing. Statistical side all working (if slow).
7/4/2004: Algorithm really is too slow to be useful. It needs to be fast enough to play with, try different scenarios, or it will be dangerous. Have to wait for Moore's law or find better algorithm :-(.
|
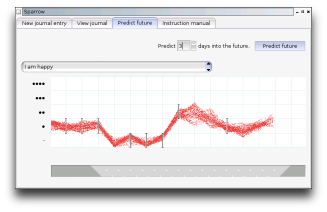
These ideas are in a state of flux, this is my thinking as of when i last updated this page. I'm interested in any comments and critiques. As always, feel free to steal any ideas in these pages. The very reasons that I'm interested in this also mean that I may not be able to follow through on it -- a competing project or two would make me very happy. My motivation for all this will, I think, be obvious to some people: you know who you are.
What and why
 The name "Sparrowfall" should give you a fair idea, but to state it formally: software and/or a website to provide
The name "Sparrowfall" should give you a fair idea, but to state it formally: software and/or a website to provide
- Very large scale, ad-hoc medical data collection
- Statistical analysis of this data, paying particular attention to reporting bias, for the prediction of future outcomes, and the effect of various treatments and choices on these outcomes
The initial focus is on mental illness, since this is an area in which conventional medicine is weak (and because I have a personal stake in this area). Also chronic illnesses, such as chronic pain or athritis.
Some things that Sparrowfall is not:
- Unless I'm really really lucky, it is not going to be considered conventional medicine for some time
- However, neither is it "alternative" medicine, since it will actually work (or at least be able to predict that it won't work)
- Sparrowfall is not anonymous
The aim is for something of equivalent power to our current system of double blind placebo controlled studies, but of far larger scope. A double blind study eliminates bias due to the placebo effect and selective reporting of results, to study a single effect. Sparrowfall instead aims to accurately model the placebo effect and reporting bias, by taking into account factors such as personality traits, producing a more complete model. Sparrowfall assumes people will try out all sorts of wacky random things and believe strongly in all kinds of wacky random things, so that the effects of belief can be factored out (or even used therapeutically). This is not an unreasonable assumption.
- To gain scientific legitimacy, Sparrowfall will have to be validated by double blind placebo controlled studies.

Starting points
A simple starting point would be some software to record one's day to day condition. Things such as how long you slept, how you are feeling, what you are doing, any medications you are taking.
- Probably written in Python
- Would be useful if it ran on Palm-pilots, mobile phones and so on.
Care will have to be taken over temporal reporting biasses (eg reporting while happy, but not while depressed, the validity of volunteered vs asked for information) (see Blog).
So, we have collected some data. Suppose we then construct a Markov model:
- A 1st order Markov model, P(current state vector -> state vector at t+1)
- A reporting bias model of some form P(reporting of particular elements in state vector | state vector)
The ontology here is that a person is considered as a state vector evolving over time. We have partial data of that state vector at some times.
To model many people at once (i.e. the full Sparrowfall system), add entries to the state vector indicating which person they are -- eg the person at this time is in a state of Paulness (and this state is connected to past and future states that also are in a state of Paulness). This lets the system taylor itself to individuals, without further complication to the modelling thingy.
The state vector has high dimension. Therefore, we can not just tabulate the Markov model -- a less complex model is required.
The method for constructing the model must be valid, eg Minimum Message Length is ok, but *not* Maximum Likelyhood. Alternatively, the model is constructed in an ad-hoc way, then validated (eg feed in half the data, try on remaining half) to give some kind of trust level.
The simplest valid method would be to construct a correctly distributed sample of possible models given the data. One can then examine the samples, measure means, medians, variances, etc of each parameter to determine a "best" model and how sure we are about it, or test hypotheses against the sampling itself.
The Metropolis Algorithm can do this. The only caveat is knowing at what point to stop sampling (and I'm sure someone has studied this). Also it might be slow.
The "burn-in" phase might be supplimented by an ad-hoc algorithm for choosing a good initial model.
Once we have this model we can then pose and compare hypotheticals, eg:
- What would happen if I took panadol daily?
- What would happen if I did not take panadol?
- maybe even: What would happen if I took panadol occasionally as appropriate?
and calculate a probability distribution of outcome trajectories (probably by generating a large set of synthetic state sequences into the future, then averaging -- high dimensionality is a bitch). We could then compare, eg:
- Am I on average happier in one scenario than another?
and also be able to decide if any differences are significant (ie P(H0) html < .01 or so).
We can also approximately fill in the unknown values in the data collected, in order to analyse it directly (rather than the model).
Notes on statistical inference
 Bayes. Occam.
Bayes. Occam.
Maximum Likelyhood is only useful when then model is limited in size. In this case it might choose the best model in the limit as more data is collected, or it might not. Without a limit on model size, it will choose infinitely complex models in the limit.
Minimum Message Length will converge on the correct model in the limit, even without a limit on model size. It also seems fairly good with limited data. However it is *not* the optimal way to make predictions given limited data.
Optimal inference where data has no missing values:
- Find all P(model i | data) or density(model i | data)
- Predict one step into future by summing (or integrating): sum P(model i |data) P(new datum | model i)
- Predict more than one step into future by summing over state distribution at previous tick
-- first item may be approximated by using the Metropolis algorithm to generate a set of sample models. These can be fed into the second item. With sufficient time and computing resources, this method looks like it will produce optimal predictions about the future, with any amount of data.
Optimial inference with missing values:
The things we need to work out are:
- The parameters of the model
- The missing values
These will have to be optimized in tandem, since the space of states is so large (high dimensional).
Is even this feasible?
Fun things to consider:
- Say the first state is missing. Can we choose whatever state we like? No: our choice will affect our expectation of the next state. So inference has to be able to propogate back in time as well as forward. Tandem Metropolis sampling will handle this. Non-tandem will not (non-tandem may not even make sense at all).
- Say a person's future could potentially fork. Eg, they might die of cancer or recover. We want samples of both these cases. Metropolis might have a hard time flipping between them.
A tentative structure for the model:
This is extremely similar to my PhD work on image de-noising. I'm in the middle of writing that up, and will try to post it here once it's done.
We have a sequence of states, each containing a set of measurements (the same set for each state). These measurements are real valued. Let us order all of the measurements, by writing each state in turn, and within each state writing each measurement (in arbitrary order, but consistent between states). Then we may calculate the probability density by calculating the density of each measurement given the preceding measurements.
S1 S2 S3 S4 ... m1 m1 m1 m1 ... m2 m2 m2 m2 ... m3 m3 m3 m3 ...
To represent discrete values, such as a binary choice, partition the number line. For example less than -1 is false, greater than 1 is true, in-between is fuzzy.
-1 1
Or for a choice with more options, which is ordered
1.5 2.5 3.5 4.5
<111111|222|333|444|555555>
Note that there are no bounds on a measurement.
When the user enters some data, this constrains the value of a measurement. For example, if to the question "Are you male?" they answer "true" then the maleness measurement at that time must exceed 1. Or if when asked "On a scale of 1 to 5, how happy are you?" they answer "4" then the happiness measurement at that time is constrained to lie between 3.5 and 4.5.
How shall we decide the density of each measurement (and of the model)?
A simple way would be to produce for each measurement a prediction of its most likely value, based on a linear sum of preceding measurements in our ordered list of measurements. This sum need not include all preceding measurements, just measurements in this state and the preceding several should suffice. Then let us say that the difference between the predicted and actual values tends to be normally distributed. So our probability density function for each measurement is a Gaussian distribution centered on the prediction.
Our "texture" model is the weights used in each linear sum. We have a linear sum for each of the measurement types, comprising weights for preceding measurements in the current state (according to an arbitrary ordering), and weights for measurements in previous states, and weights for information such as which questions the user answered.
We need to calculate the densities for the weights that comprise the model. A reasonable guess would be that they have a Gaussian or two-tailed exponential distribution about zero.
The densities for each weight in the model, and each measurement in the sequence of states are multiplied together, giving an over-all density.
And this is all we need :-)
Why this form of model?
- It is simple.
- It has a reasonable number of parameters, O(n^2) where n is the number of measurements per state.
- It has a beautiful symmetry. I still need to check this, but i think it's invariant under re-ordering of measurements within states, and under reversing the time axis.

Things to track
A large set of yes/no or 1/2/3/4/5 type questions. There should also be an option not to answer a question. The system will have to be able to select a set of questions that are likely to give information. Also the person using the system should be able to voluntrarily answer other questions (and add new questions).
- Have to give an oportunity to note any fact a person wants to. People will often have something they really want to note. If an appropriate option is not given, they will most likely fudge a similarish question, thus distorting the data set. Also, it must be possible not to answer a question, for example if it is too sensitive, or one simply does not know the answer (in which case it should be possible to find questions that alude to this un-answered question, or get at it a different way).
Questions have to refer to a time frame. eg in the last 24 hours, in the last week, etc. This could be part of the question. Alternatively it could be used to constrain the state vector, i.e. the person's state is entirely missing data, but has constraints.
Below are some possibilities. See also the book "Authentic Happiness" by Martin Seligman.
Goal type items:
- I am of good cheer.
- I am in pain.
- My life is worthwhile.
- I'm getting some good flow happening.
Resolutions (Sparrowfall's primary function would be to give estimates of the effects of these on the goal items):
- I have resolve to give up smoking.
- I have resolve to see a GP/psychiatrist/dentist/etc.
- I have resolve to obtain and use medication X/Y/Z.
- I have resolve to henceforth be a happy bouncy person.
Other:
- I slept at least 7 hours. (etc)
- I slept well.
- When I woke, I remembered dreaming.
- I am having nightmares.
- I had trouble getting to sleep.
- I had trouble getting up.
- I did some exercise.
- I am overweight.
- I don't feel like i have enough energy.
- I have an excess of energy.
- I have a lack of energy in the mid-morning/late-afternoon/etc.
- I smoked.
- I smoked a lot.
- I smoked something that was not tobacco (some legal problems here, given lack of anonymity).
- I have diarrhea/constipation (some taboo problems here, even i get embarassed saying i have diarrhea).
- I am taking medication X/Y/Z.
- I am consulting a GP/psychiatrist/etc.
- I do yoga/acupuncture/reflexology/massage/reflexology/dianetics/tai-chi/.
- It is spring/summer/autumn/winter/The-Wet/The-Dry.
- My latitude is approximately ... (important for SAD).
- I live in a rich/intermediate/poor nation.
- I have access to health care.
- I have enough money to get by.
- I am young/middle-aged/getting-on/old.
- I'm a girl/guy/etc.
- I am Tom/Dick/Harry.
and so on. It should be easy for people using Sparrowfall to add items addressing their own very specific concerns. People should also be able to enter a blog entry: even though this can't be analysed, other people can read it.

References
www.remedyfind.com Closest thing to Sparrowfall existing today. The statistics are not perfect, but this is more than made up for by the value of the comments people write about each remedy.
Authentic Happiness questionaire site A tie in to a popular psychology book by Martin Seligman. Provides facility for tracking changes in response to various psychological questionaires. Alas, he's still hung up about the whole privacy thing, and the web-site is kind of clunky. But the guy is a psychologist, so he probably knows his statistics.
Gawande, A. (2002), Complications Very readable account of the methods and culture of surgery. Of particular note:
- Computer modelling beats human intuition in certain specific cases, for example diagnosing ECGs.
- The things that ail people are vast in number, and many still mysterious and largely untreatable. Palliative care is noted as one of the fields that has made significant progress.
- An account of the gradual stressing out and deteriorating judgement of someone under a very heavy work load (a surgeon, but it can happen to anyone). Hospitals now look for warning signs of this in surgeons. Hopefully a Sparrowfall system would also pick up on the early symptoms of stress and give a warning.
Horton, R. (2003), Second Opinion

Less definite thoughts
Full success would be a very strange thing:
- Breaking the anonymity taboo is a big shift, but with the phenomenon of blogging, this seems to be happening already. Various new technologies will require a total surveilance police state fairly soon anyway (biotech, nanotech, nuclear material), so we may as well start working out how to get it right now. Hopefully this will take some of the loneliness and stigma out of fighting disease, but it's such a huge change that it's hard to say what the effects will be.
- The balance of power between doctors and patients shifts, it is no longer a situation where the doctor renders his judgement and the patient obeys (taking on trust that the doctor knows his stuff). Again, this is already happening due to the large amount of medical material available on the web. This material is often of dubious quality however. Sparrowfall aims to be a serious, provably correct alternative to the usual statistical methods of science.
- Participants in Sparrowfall are not "Subjects", they have names and stories. The full diversity and depth of personality is acknowledged. An important aspect of Sparrowfall will be as a set of blogs, the personal stories of many different people in their own voice. This is in marked contrast to standard medical studies, where the S's are anonymous and objectified (for example, by referring to them by their initials).
- Sparrowfall will tend to bleed outside of strictly medical questions. With enough data, it might be able to answer questions about lifestyle ("you should exercise more/less/differently"), relationships ("dump him you idiot", "here's someone you'd probably be friends with, why not have a chat with them?") and so on. This is somewhat reminiscent of Iain M. Banks' "Culture Minds". People remark about the omniscience of Google. A successful Sparrowfall system would be far scarier.
Let's take this wild speculation just that one step further. A few decades down the track, we've gone through several generations of increasingly precise models as Moore's law continues it's steady progression, and started gathering truely massive quantities of data. Sparrowfall-2020 is pretty cluey. What does that mean?
- Ok, so we have a system that can (among other things) simulate what choices you will make. It has a great deal of data about your life, and can fill in the gaps fairly well by looking at other people's lives. What if, when you die, it takes over from where you left off? Greg Egan came up with a lovely phrase that is relevant here: "simulated addition". If it can simulate you precisely, then it can be argued that it is you. Cheap-ass immortality :-)
You and what army?

This is obviously a fairly big project. Here are some possibilities (a sampling of future trajectories if you like :-) ):
- I nut away at it slowly, getting money from a day job. RMS's "waiting on tables" solution. This will obviously be fairly slow.
- By some miracle I finish my PhD and go on to postdoc/etc in at least the statistical and computational aspects of this (which are interesting problems in themselves). The application as actual free software i do in my own time. Still fairly slow.
- Someone else who is more stable than me does it for me. Or collaborates with me for that matter.
- A well-to-do patron with a chronic, treatment resistant illness decides this whole thing has an outside chance of working and is worth investing in. You for instance, you made your fortune by dint of your barely controlled manic and hypo-manic episodes. These (and other indignities) have lead to a, let us say, difficult personal life. You've tried all the standard medications, seen the top doctors (and wasted even more money and effort learning the difference between snake-oil and science), and are looking for something completely orthogonal to everyone else's methodologies. How about dropping me an email?