This is a form of generalization or abstraction that is a step along the way to language. I'd like to think here not just about human language but the language of the body, such as hormones.
The correspondence between these vectors and and chemical messanging in the body is quite a nice one. Consider a chemical in the body, or a value in one of these vectors. At first it is secreted more or less randomly / takes on random values. Then two things happen: 1. Where it happens to have predictive value, it is used more (via evolution / numerical optimization). 2. Based on how it is used, the pattern of secretion / value assigned is adjusted (again via evolution / numerical optimization). As this process iterates, a useful meaning emerges.
One might suppose much the same thing happens in human language also.
Since it is possible to arbitrarily rotate these vectors in such a way as to produce exactly the same results, I don't feel it would be right yet to equate the elements in these vectors with distinct words in the English language or chemical messages in the body. However, consider the scatter plot below, showing two elements of a four element vector describing movies in the NetFlix dataset:
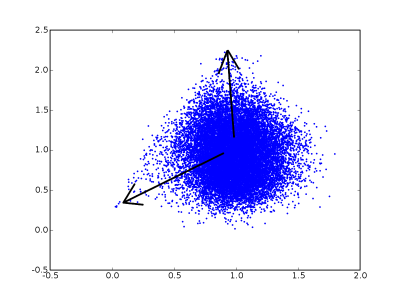
Note how it is not simply a Gaussian blob. It has two protrusions, marked with arrows, as though it is the sum of two random variables with one fat tail apiece (eg skew-alpha-stable or skew-t).
I suspect that in the case of chemical messages, fat tailed meanings will tend to become axis aligned, as this will be easier to evolve. In the case of human language, axis aligned fat tails would be simpler to use and remember.
So if the protrusions above were axis aligned, thus disentangling those two random variables (aka ICA), then I would feel happy putting elements in these vectors on the same level as words and chemical messangers.